

When AI Does the Work, What Does the Credential Certify?
Institutional Effectiveness Weekly | Edition 42

Credentials are economic signals. They are supposed to tell employers something they cannot observe directly: that a person completed a course of study and demonstrated the competencies it was meant to produce. The signal has always been imperfect. Grade inflation, inconsistent standards, and the gap between what a transcript says and what a graduate can do have been documented problems for decades. Edition 24 of this newsletter identified those problems as the core of the demonstration gap: higher education’s failure to prove, credibly and independently, the outcomes it produces (Rudawsky, 2026a).
The ROI Paradox trilogy in Editions 25 through 27 showed how student behavior, institutional incentives, and grade inflation compound that gap into a structural credential reliability crisis (Rudawsky, 2026b; Rudawsky, 2026c; Rudawsky, 2026d). Generative AI has not created a new problem. It has compressed the timeline on an old one and made the underlying question impossible to ignore: when a student submits AI-generated work and earns a grade for it, what does that credential certify?
Recent employer research makes the stakes concrete. Aviva Legatt, founder of EdGenerative and affiliated faculty at the University of Pennsylvania, synthesized three converging data sets on this question. Working from a Pearson and Amazon Web Services survey of 2,700 respondents across six countries, a Strada Institute survey of nearly 1,500 senior talent leaders, and Graduate Management Admission Council (GMAC) data on what employers expect to value most on a five-year skills horizon, Legatt argued that the distinction institutions need to make is between AI literacy and AI fluency. Literacy is the floor: the ability to open an AI tool and prompt it. Fluency is the differentiator: the capacity to apply AI to domain expertise, pressure-test an analysis, catch a flawed recommendation, and defend why the tool’s first answer was wrong (Legatt, 2026a; Legatt, 2026b). The GMAC survey, drawing on 1,108 corporate recruiters and hiring managers across 46 countries, found that knowledge of AI tools topped the list of skills employers expect to value most five years from now, with one of the steepest year-over-year gains in perceived importance of any skill tracked (GMAC, 2025).
Only 14% of graduates report high proficiency applying AI in a professional workflow (Pearson & AWS, 2026). That figure identifies the demonstration problem with unusual precision. This edition examines the AI credential signal quality problem as an institutional effectiveness challenge, not a technology challenge. The tools have changed faster than any planning cycle could have anticipated. The question now is how existing assessment infrastructure gets oriented toward the new problem. To that end, this edition proposes an original AI Fluency Assessment Framework: four dimensions with three levels each, built on the convergent evidence from this edition’s sources and designed to map directly onto the ASLO and VALUE rubric infrastructure institutions already operate.
The Perception Gap That Should Concern Provosts
The Pearson and AWS AI Readiness: Building the Bridge from Higher Education to Work report drew on more than 2,700 survey responses across six countries. Its most consequential finding is about institutional self-assessment: 78% of higher education leaders believe their institutions are meeting employer expectations on AI readiness. Only 28% of employers agree (Pearson & AWS, 2026). That 50-point perception gap is the credential quality problem restated in institutional terms, and it recurs across the demonstration gap literature in different forms. Edition 32 documented a similar internal contradiction in the IHE presidential survey data on cost transparency: 84% of presidents rated their institution’s cost transparency as good or excellent, while only 27% of students said they fully understood their cost of attendance (Rudawsky, 2026e). Institutions consistently overestimate how legible their outputs are to external audiences.
The Strada Institute’s Entry-Level Hiring in the AI Era report, drawing on nearly 1,500 executives and senior talent leaders surveyed in spring 2026, clarifies what employers are looking for in concrete terms. Among employers that had explored using AI, 42% reported that analytical and judgment-based responsibilities for entry-level employees had grown; 41% reported that routine and administrative tasks had shrunk (Strada Institute, 2026). Entry-level hiring volume is not collapsing. Employers expecting AI to increase entry-level hiring outnumber those expecting decreases by nearly three to one. What has changed is the selection inside that volume. The tasks that AI has taken over are precisely the tasks that new graduates used to use to develop judgment. Employers are hiring, but for the competencies that remain after AI handles the routine work.
Legatt’s synthesis produces a pointed observation: AI literacy ranks last in employer importance not because employers don’t need it, but because they assume graduates can already open an LLM and type a prompt. The bar has moved without most institutions registering it (Legatt, 2026a). This is the demonstration gap framing at the competency level: the problem is not whether the skill exists but whether institutions are producing and certifying the right skill.
The Scale of Student AI Adoption
Stephenson and Armstrong (2026) reported that 94% of UK undergraduate students use generative AI to help with assessed work (Stephenson & Armstrong, 2026). This behavior spread faster than any institutional planning process was designed to absorb.
Institution-level data from the 2026 Inside Higher Ed/Hanover Research Survey of College and University Presidents adds context on where institutions currently stand. Presidents report that 18% of institutions are using AI for grading and assessment and 13% for personalized learning pathways, compared to 58% using AI for virtual chat assistants and 47% for administrative processes such as scheduling and resource allocation (Inside Higher Ed & Hanover Research, 2026). Separately, only 19% of presidents agree that higher education as a whole is responding adeptly to the rise of AI, though 55% believe their own institution is (Inside Higher Ed & Hanover Research, 2026). The pattern is consistent with a sector where individual institutions feel relatively prepared while recognizing that the sector collectively is not.
The combination of near-universal student AI use and still-developing institutional assessment adaptation describes a transitional moment, not a permanent failure. Students have moved quickly. Institutions are working out what the right response is. The question worth asking from an IE perspective is which existing infrastructure can be redirected toward this problem rather than what needs to be built from scratch.
What a Grade Certifies When AI Does the Work
The economic function of a grade is to certify that a student demonstrated a competency. The instructor evaluates the work; the grade records the evaluation; the transcript aggregates the grades. In practice, employers have largely stopped relying on this chain. WGU employer research found that while 68% of employers say degrees are important, only 22% rely on educational credentials when assessing whether candidates have required skills. Employers consistently rank on-the-job evaluation (41%), technical or skills-based assessments (40%), and portfolios (28%) above credentials (22%) in their actual hiring process (WGU, 2024). The transcript is not just an imperfect signal. For most employers in most contexts, it is a bypassed one.
This employer behavior predates AI. What AI has changed is one structural feature of the problem: it has dramatically reduced the effort required to produce work that looks credible. A student who copied from a peer or purchased an essay was making a costly, detectable choice. A student who prompts a large language model and submits the output lightly edited is making a low-cost, minimally detectable choice. The threshold for producing a plausible artifact has dropped substantially, while the threshold for demonstrating genuine competency remains exactly where it was.
This is not primarily a student character argument. The ROI Paradox series established that students respond rationally to the environments institutions create (Rudawsky, 2026b). When the incentive is to complete an assignment and AI makes completion trivial, the rational student response is to use AI. McCabe, Butterfield, and Treviño’s (2012) comprehensive research found that 68% of undergraduate students already admitted to cheating before AI tools were available. Generative AI accelerated an existing pattern, not a new one.
Fajardo-Ramos, Chiappe, and Mella-Norambuena (2025) argued that when AI can replicate the surface features of competent work, the relevant distinction shifts from product quality to process evidence. Grading a final essay tells you what text was submitted. It does not tell you who produced the reasoning, or whether the student could reproduce it in a different context (Fajardo-Ramos et al., 2025). This connects directly to the Legatt literacy/fluency distinction: a grade earned on AI-assisted work may certify literacy. It cannot certify fluency, because fluency requires the student to have done the reasoning.
The Transparency Signal and the Demonstration Gap
Kristina Powers, founder of the Institute for Effectiveness in Higher Education, developed the Powers Index of College and University Performance as a framework for evaluating institutional health across 12 signals in four domains: Data, Governance, Fiscal, and Environment (Powers, 2026). Signal #2 in the Powers Index is Transparency, defined as clear and accessible institutional reporting. The demonstration gap, as this newsletter has argued since Edition 24, is most precisely understood as a Transparency failure for the external audience that matters most: employers and families.
The distinction the Powers Index makes visible is between Signal #1 (Monitoring, defined as consistency of performance oversight) and Signal #2 (Transparency). For most accredited institutions, Monitoring is functioning: ASLO cycles run annually, VALUE rubric assessments generate program-level outcome data, and accreditation reports document what students are learning. The gap is not in the Monitoring infrastructure. It is in what happens next. That evidence stops at the accreditor. It is never routed to the people making hiring decisions.
The AI credential quality problem maps directly onto this framework. Institutions are monitoring student performance through assessment cycles that predate AI. The Transparency question is whether those assessment systems are designed to surface evidence that addresses the new problem: not just whether a student completed an assignment, but whether the student demonstrated reasoning that a credentialing mechanism can verify as theirs. The ASLO infrastructure already exists at every accredited institution. The design question is whether assessment rubrics and assignment structures are generating evidence that is legible to external audiences, and specifically whether they produce anything that survives the AI substitution test.
Toward an AI Fluency Assessment Framework
The literacy/fluency distinction Legatt identifies (Legatt, 2026a) is analytically useful but requires operationalization to be useful in an assessment context. What does fluency look like when an instructor is designing an assignment or a program is reviewing its assessment architecture? The following rubric proposes four dimensions of AI fluency, each with three levels, intended as a starting point for faculty and assessment teams rather than a finished instrument.
The four dimensions are drawn from the convergent evidence in this edition: Output Evaluation (from Fajardo-Ramos et al.’s process-evidence argument), Judgment Override (from Legatt’s Forbes analysis of what employers cannot find in the current graduate population), Domain Integration (from the Pearson/AWS finding that AI access has not translated into applied workplace capability), and Process Transparency (from the Powers Index Transparency signal and the broader demonstration gap argument). The levels track a progression from surface tool use to the kind of applied judgment the Strada Institute data identifies as what entry-level roles now require.
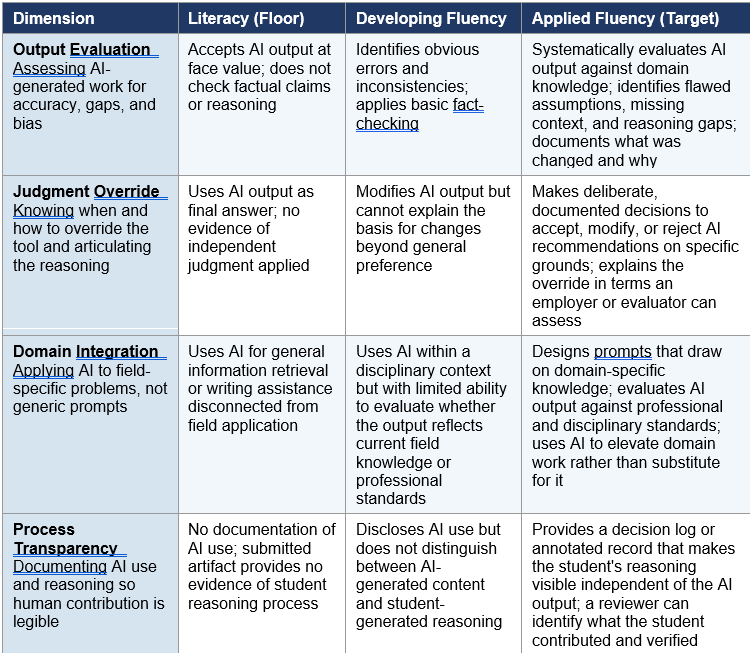
A fifth dimension worth considering as institutions develop their own versions is Ethical Calibration: the capacity to identify situations where AI use is inappropriate, biased, or high-stakes enough to require unassisted human judgment. This is the dimension most directly engaged by Legatt’s observation that employers need graduates who know when to override the tool, not just how. It is also the dimension most dependent on field-specific norms and hardest to assess without direct faculty expertise in the relevant domain.
These dimensions align with the AAC&U LEAP VALUE rubric framework, which covers critical thinking, ethical reasoning, and integrative learning as distinct assessable outcomes. Institutions already using VALUE rubrics for ASLO compliance have a natural entry point: the AI Fluency dimensions map onto existing rubric infrastructure rather than requiring parallel systems. The Judgment Override and Process Transparency dimensions are particularly close to the Critical Thinking and Integrative Learning VALUE rubrics. The design work is not starting over. It is asking whether current rubric applications generate evidence that is legible in an AI-saturated assessment environment.
Assessment Design and the Existing Infrastructure
Detection tools are not a durable solution. The arms-race dynamic between detection technology and generation technology favors generation over time. The more durable institutional response is assessment redesign that shifts verification from artifact quality to demonstrated process.
Legatt identifies four specific curricular moves worth considering (Legatt, 2026a). First, build evaluable artifacts into the degree audit: every graduating student should leave with work produced under real constraints, each with a documented decision trail. Second, rebuild the formation environment that AI has removed from workplaces: Strada finds 33% of employers report AI has reduced foundational skill-building tasks for entry-level employees, which means the developmental experiences that used to happen on the job now need to happen in the educational setting. Third, embed AI use inside judgment-heavy courses and assess the override rather than the prompt: a finance course should require students to use AI to produce a valuation and then defend why they overrode the AI’s recommendation on specific assumptions. Fourth, treat math-intensive STEM attrition as a gateway-course problem rather than a program content problem, since most of the pipeline loss happens between calculus and second-year sequences, not in upper-division coursework.
These design principles address the literacy/fluency distinction directly. They are designed to certify that the student did the reasoning, not just that the submitted artifact was competent. Fajardo-Ramos et al. (2025) identify the same features: analysis and synthesis requiring original contextual judgment, process documentation, oral defenses, and application to novel contexts where pattern matching fails (Fajardo-Ramos et al., 2025).
The critical point for institutions navigating this quickly is that none of this requires new infrastructure. Every accredited institution runs ASLO cycles. Every institution using VALUE rubrics already has a framework for assessing critical thinking, ethical reasoning, and integrative learning. The design question is whether those rubric applications are generating evidence legible to employers, and specifically whether they produce anything an employer can evaluate without a translation layer. That is the Transparency gap in the Powers Index framing: the monitoring is running. The question is whether it is producing anything that reaches the right audience in a usable form.
The IE/IR Role in This Conversation
IE/IR offices do not own curriculum or assessment design. Faculty own what is taught; assessment offices lead the methodology infrastructure; academic affairs coordinates program review. The IE role is to provide the evidence that makes the problem visible and the alternatives legible.
Three areas of analytical contribution follow from the evidence in this edition.
Program-level AI readiness audit. The Pearson/AWS finding that 78% of institutional leaders believe they are meeting employer expectations while only 28% of employers agree (Pearson & AWS, 2026) is a sector-level perception gap. IE offices can produce the program-level version: mapping current assessment designs against the AI Fluency dimensions above, identifying which programs already generate process-based evidence through clinical placements, oral defenses, portfolio review, or external credentialing exams, and which programs rely primarily on submitted artifacts that the AI substitution problem directly affects.
Employer signal tracking. The Strada Institute finding that entry-level roles are shifting toward analytical and judgment-based work (Strada Institute, 2026) is a labor market signal that belongs in program review cycles. IE offices that maintain employer relationship data and track first-destination outcomes can translate sector-level evidence to the program level, connecting graduate outcomes to the specific competencies the current labor market is selecting for.
ASLO-to-demonstration gap analysis. The gap between Signal #1 (Monitoring) and Signal #2 (Transparency) in the Powers Index is exactly what this analytical work diagnoses. IE offices that track student-level learning outcome data have the infrastructure to ask: does the evidence our assessment cycles produce say anything useful to an employer about what this graduate can do? If the answer is no, the assessment architecture is worth examining before it becomes a regulatory question. AHEAD rulemaking concluded in January 2026 with a 12-0 consensus vote establishing earnings-based accountability benchmarks for every program. Institutions that treat demonstration as a voluntary quality improvement question rather than a fiduciary one are working against a tightening timeline.
What This Means for the Demonstration Gap
The demonstration gap thesis holds that higher education’s core challenge is not producing outcomes but proving them credibly and independently. AI sharpens that argument in one specific way: it makes credibly harder. When surface-level work quality is achievable through AI assistance, the credibility of credential evidence depends more than ever on the verification mechanism behind it.
Legatt’s literacy/fluency distinction maps directly onto the visibility dimension of the demonstration gap. A transcript documents course completion. It does not document whether the graduate can apply AI to domain expertise, pressure-test an analysis, or override a flawed recommendation. These are the competencies the Pearson/AWS and Strada Institute data identify as what employers cannot find (Pearson & AWS, 2026; Strada Institute, 2026). They are also the competencies most directly certifiable through assessment designs that survive the AI substitution test.
Institutions that respond to AI by asking how their existing assessment infrastructure can be redesigned to generate more legible competency evidence are closing the demonstration gap. Institutions that respond by issuing AI use policies and deploying detection tools while leaving rubric and assignment design unchanged are not. The credential they issue will certify something. The question is whether the employer reading it, if they read it at all, has any reason to trust what it claims.
References
Akerlof, G. A. (1970). The market for “lemons”: Quality uncertainty and the market mechanism. Quarterly Journal of Economics, 84(3), 488-500. https://doi.org/10.2307/1879431
Fajardo-Ramos, D. C., Chiappe, A., & Mella-Norambuena, J. (2025). Human-in-the-loop assessment with AI: Implications for teacher education in Ibero-American universities. Frontiers in Education, 10, 1710992. https://doi.org/10.3389/feduc.2025.1710992
Inside Higher Ed & Hanover Research. (2026). 2026 survey of college and university presidents. Inside Higher Ed. https://www.insidehighered.com/reports/2026/03/09/2026-survey-college-and-university-presidents
Graduate Management Admission Council (GMAC). (2025). 2025 Corporate Recruiters Survey: Summary report. GMAC. https://www.gmac.com/-/media/files/gmac/research/employment-outlook/2025-corporate-recruiters-survey/summary-report.pdf
Legatt, A. (2026a, May 28). Why AI fluency, not literacy, is the differentiator: 4 moves for higher ed. Forbes. https://www.forbes.com/sites/avivalegatt/2026/05/28/why-ai-fluency-not-literacy-is-the-differentiator-4-moves-for-higher-ed/
Legatt, A. (2026b, June 8). AI literacy is the floor. Fluency is the differentiator. Almost no institution is producing it yet. Higher Ed AI Playbook.

McCabe, D. L., Butterfield, K. D., & Trevino, L. K. (2012). Cheating in college: Why students do it and what educators can do about it. Johns Hopkins University Press.
Pearson & Amazon Web Services. (2026). AI readiness: Building the bridge from higher education to work. https://www.pearson.com/content/dam/global-store/global/resources/ai-readiness/AI-Readiness-Report-2026.pdf
Powers, K. (2026). Powers Index of College and University Performance. KP Powers. https://kppowers.com/powersindex/
Rudawsky, D. (2026a). The demonstration gap: Why higher education’s biggest challenge isn’t developing skills, it’s proving it. Institutional Effectiveness Weekly, Edition 24. https://donrudawsky.substack.com/p/the-demonstration-gapwhy-higher-education
Rudawsky, D. (2026b). The ROI paradox, part 1: When career preparation becomes credential collection. Institutional Effectiveness Weekly, Edition 25. https://donrudawsky.substack.com/p/the-roi-paradox-part-1-when-career
Rudawsky, D. (2026c). The ROI paradox, part 2: When do credentials stop working? Institutional Effectiveness Weekly, Edition 26. https://donrudawsky.substack.com/p/the-roi-paradox-part-2-when-do-credentials
Rudawsky, D. (2026d). The ROI paradox, part 3: Making credentials demonstrate competence. Institutional Effectiveness Weekly, Edition 27. https://donrudawsky.substack.com/p/the-roi-paradox-part-3-making-credentials
Rudawsky, D. (2026e). Trying harder isn’t a strategy: What the presidents survey reveals about higher education’s trust execution gap. Institutional Effectiveness Weekly, Edition 32. https://donrudawsky.substack.com/p/trying-harder-isnt-a-strategy-what
Rudawsky, D. (2026f). The infrastructure is already there. Institutional Effectiveness Weekly, Edition 34. https://donrudawsky.substack.com/p/the-infrastructure-is-already-there
Stephenson, R., & Armstrong, C. (2026). Student generative AI survey 2026 (HEPI Report 199). Higher Education Policy Institute & Kortext. https://www.hepi.ac.uk/wp-content/uploads/2026/03/HEPI-Report-199-Gen-AI-Survey-2026.pdf
Strada Institute for the Future of Work. (2026). Entry-level hiring in the AI era: What employers are thinking (and doing). Strada Education Foundation. https://www.strada.org/news-insights/entry-level-hiring-in-the-ai-era-what-employers-are-thinking-and-doing
Western Governors University. (2024). Skills-based hiring and the future of credentials. WGU. [Plain-text citation only due to URL instability; available at wgu.edu/about]